1. 네트워크 계층 개요
우선 네트워크 계층에 대해 간단히 복기하고 넘어가보자!
# 네트워크 계층에선 데이터가 향할 주소를 설정하고, 이로 향할 최적의 경로를 선택한다! 전자에 관련된 것이 IP주소, 후자에 관련된 것이 Routing인 것이다!
# 3 계층에서 활용하는 데이터의 단위는 패킷 Packet으로, 이전 계층의 Frame에 캡슐화, 또는 다음 계층의 Segment에 역캡슐화가 이뤄진 것이다! (캡슐화는 계층별로 데이터를 인식하기 위한 명찰(=Header)을 붙이는 과정을 의미함!)
# 관련된 프로토콜로는 IP주소를 통해 MAC주소를 찾아 라우팅의 효율성을 높여주는 ARP, 통신 오류 점검하는 ICMP, 소속 통신망을 알려주는 IGMP 등이 있었다!
오늘은 주요 특징인 IP주소와 Routing에 대해 상세하게 쉽게 재밌게 알아볼 예정인 것이다!
2. IP 주소 Internet Protocol Address
2-1. 등장 이유
동일 네트워크, 즉 네트워크 내 통신에선 MAC 주소만으로 왔다갔다가 가능했지만,
넓은 세상인 네트워크 간 통신에선 MAC 주소만으로는 "모든 네트워크"의 "모든 호스트"를 특정하기 어려워진다!
게다가 호스트는 언제라도 소속 네트워크가 달라질 수 있기 때문에 길찾기가 더 혼란해지는 것이다!!
이에 이런 가변적인 상황에 유연하게 대처할 수 있는 논리적 주소, IP Address가 등장한 것이다!!
2-2. Internet Protocol의 기능
IP의 기능은 크게 두 가지로, 주소 지정 addressing과 단편화 fragmentation가 있다!
각각의 개념을 간단히 알아보고, IP 체계를 구분한 후에 마저 자세히 알아보는 걸로!!
주소 지정 addressing
간단히 생각하면, 누가 보내고, 누가 받을 지를 특정하기 위해 출석번호를 매겨주는 것과 같다!
어떤 체계의 주소냐에 따라 표현 양식이 다르지만, 공통적으로 여러 개의 비트(=0,1)를 바탕으로 구분하게 됨!
정적 할당과 동적 할당
주소 지정을 사용자가 직접하면 정적 할당, DHCP 프로토콜을 통해 자동으로 받으면 동적 할당이라고 한다!
DHCP (Dynamic Host Configuration Protocol), 이름도 길다, 무튼 이 DHCP 서버에 IP 주소를 요청하고, 이를 임대받는 방식이고, 매 임대마다 만료 기한이 존재하고, 주소도 달라지곤 한다!!
구명조끼 빌리면 영업 종료 전에 반납해야하고, 빌릴 때마다 같은 거 찜꽁해서 받지도 못하잖어? 그런 거다!!
단편화 fragmentation
전송하려는 패킷의 크기가 넘 클 때, 요 녀석을 더 작게 분할해서 여러 개로 나눠 보내는 것을 말한다!
단편화된 패킷들은 각각이 가진 정보를 통해 수신지에서 재조립된다!! 이 정보들은 이후 자세히 알아보도록 하겄다!!
소형 택배 상자 사놓고 냉장고를 통째로 넣을 순 없는 모양이잖어?
안에 든 과일이나 간식들을 꺼내서 여러 상자에 나눠 담아야지... 그런 거다!!
MTU (Maximum Transmission Unit)
전송 1회마다 허용 가능한 패킷의 최대 크기, 넘 큰 게 어느 정돈지 판별하기 위한 개념!!
2-3. IPv4 주소 체계
현재 인터넷 환경에서 사용하는 IP 주소는 네번째 버전인 IPv4와, 여섯번째 버전인 IPv6 두 가지 체계로 나뉘어져있다!!
좀 더 역사가 깊고 친숙할만한 IPv4를 먼저 알아보도록 하자!!
IPv4 주소의 표현 양식

위 사진처럼 IPv4는 네 가지의 10진법 숫자로 표현된다!!
이 숫자들은 온점으로 구분돼 있으며, 각각을 하나의 옥텟 OCTET이라 부른다!!
총 4바이트 단위, 즉 32개의 비트로 표현되며, 각 옥텟이 8개의 비트를 나눠 갖는다!!
8개의 비트가 표현할 수 있는 숫자 단위가 0부터 255기 때문에, IP 주소의 숫자들이 이 범위에 속하는 것이다!!
IPv4 패킷의 주요 필드
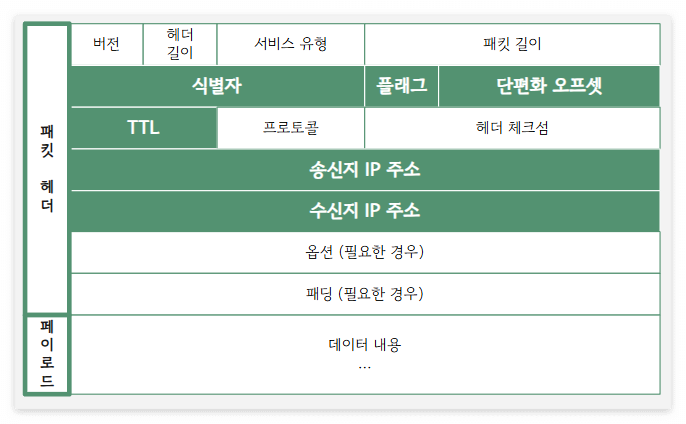
IPv4 주소의 패킷의 내용물은 위와 같고, 이 중 핵심적인 필드들 위주로 자세히 살펴보자!!
소개할 필드 이외에도 프로토콜, 송신지 주소, 수신지 주소 등의 정보가 패킷에 담기게 된다!!
식별자 identifier
단편화된 패킷들이 쪼개진 원본 데이터가 무엇인지 식별하기 위해 할당된 번호다!!
패킷들을 재조립해야하는 수신 측을 배려하기 위해 출처를 적어주는 것이다!!
플래그 flag
마찬가지로 단편화에 관한 정보가 담겨있으며, 세 개의 비트 삼형제로 구성돼있다!!
# 첫째 비트는 항상 0인 상태로, 현재 사용되지 않고 있다!!
# 둘째 비트는 DF (Don't Fragment)로, 얘가 1이면 "단편화 하지마세요!"를, 0이면 "단편화 해도됩니다~"를 뜻한다!!
# 막내 비트는 MF (More Fragment)로, 얘가 1이면 "내 뒤에 나랑 같이 쪼개진 패킷이 더 있어요!!"를, 0이면 "내가 마지막이여요~"를 뜻한다!!
단편화 오프셋 fragment offset
단편화된 패킷들이 각각 몇 번째로 분리된 패킷인지 표시해주는 번호다!!
패킷들이 꼭 순서대로 수신 측에 도착한다는 보장이 없기 때문에, 정확히 조립하기 위해선 순서 정보가 필요하다!!
우리에게 익숙한 배열의 인덱스처럼 0부터 시작해서, 숫자가 커질수록 나중에 분리된 녀석이란 뜻이다!!
TTL (Time To Live)
패킷의 수명을 나타내는 정보다!!
네트워크 환경은 냉혹해서, 쓸모를 잃은 패킷이 잔류해있는 걸 눈 뜨고 보고 있지 않는다!!
TTL은 홉 hop을 한 번 할 때마다 1씩 감소하며, 이것이 0 이하로 떨어진 패킷은 폐기된다...
홉 hop
패킷이 호스트 또는 라우터에 1회 전달되는 것! 버니홉할 때 그 홉이다!! 폴짝 폴짝!!
단편화의 한계
사실 단편화는 웬만하면 최소화하는 게 좋다!!
보내는 입장에선 불필요하게 트래픽이 증가하고, 대역폭도 낭비되니 안 좋고,
받는 입장에서도 굳이 그냥 바로 받으면 되는데, 받아서 순서 확인하고, 짝꿍들끼리 맞춰서 재조립하니 부하가 생긴다!!
식별자니, 플래그니, 단편화 오프셋이니, 애초에 단편화를 안 하면 데이터에 담길 필요가 없는 부가적인 정보들이고, 애초에 쪼개질 않았으면 다시 합쳐야하는 수고를 덜었겠지?!
따라서 우리의 통신 환경에선 단편화를 최대한 줄이기 위해 Path MTU를 활용하고, DF 비트도 켜져있는 편이다!!
Path MTU
패킷을 주고받는 경로 상에 있는 모든 장치의 MTU 중에 제일 작은 MTU를 뜻한다!!
만약 패킷을 보내는 호스트 A와 받는 호스트 B의 MTU가 모두 1000이더라도,
경로 중간에 있는 라우터 C의 MTU가 500이면 결국 패킷을 둘로 쪼개야한다...
이때 Path MTU는 500이 되고, 통신 시 패킷 크기를 500으로 제한함으로써 단편화를 방지할 수 있다!!
2-4. IPv6 주소 체계
등장 이유
IPv4 주소는 32비트니까 0 또는 1이 32개지요? 그러니 표현할 수 있는 가지 수가 2의 32승, 약 43억 개다!!
하지만 바쁘다 바빠 현대사회에선 요 정도로 전세계의 네트워크를 품기엔 부족했기에, 더 많이 표현할 버전이 필요했다!!
IPv6 주소의 표현 양식

위 사진처럼 IPv6는 여덟 가지의 16진법 숫자로 표현된다!!
이 숫자들은 콜론으로 구분돼 있으며, 각각을 하나의 헥스텟 HEXTET이라 부른다!!
총 16바이트 단위, 즉 128개의 비트로 표현되며, 각 헥스텟이 16개의 비트를 나눠 갖는다!!
이론적으로 표현할 수 있는 가지 수가 2의 128승, 겁내 많다!!
IPv6 패킷의 핵심 필드

IPv6 주소의 패킷의 내용물은 위와 같고, 이 중 다음 헤더와 홉 제한 필드를 살펴보고 넘어가자!!
다음 헤더 Next Header
상위 계층의 프로토콜 정보 또는 확장 헤더에 대한 정보를 담고 있다!! 중요한 건 확장 헤더!!
확장 헤더
기본 헤더와 페이로드 데이터 사이에 위치한 헤더로, 라우팅 효율을 증가시키기 위해 존재한다!!
확장 헤더의 구분 없이 모든 정보가 기본 헤더에 다 들어가있다면,
굳이 필요없는 정보를 매번 보게되는 경우가 생기겄지?!
때문에 헤더 열람 조건(=Option)별로 확장 헤더를 구분해놓고, 필요에 따라 열람하는 식으로 활용한다!!
확장 헤더는 체이닝 방식으로 꼬리에 꼬리를 물고 연결돼있다!!
대표적인 확장 헤더들
# 홉 간 옵션 (Hop-by-Hop Options) : 패킷의 경로에 있는 모든 네트워크 장비가 홉을 받을 때마다 패킷을 검사하도록 함
# 수신지 옵션 (Destination Options) : 패킷의 종착지, 즉 수신지에 도착했을 때만 패킷을 검사하도록 함
# 이외에도 라우팅 관련 정보 담는 Routing, 단편화 정보 담는 Fragment, 캡슐화 관련 ESP (Encapsulating Security Payload), 인증 절차 관련 AH (Authentication Header) 등이 있다!!
홉 제한 Hop Limit
패킷의 수명을 나타낸다!! IPv4의 Time To Live처럼 홉 최대 횟수를 제한함으로써 불필요한 패킷을 폐기하는 데 활용한다!!
2-5. IP 주소의 구조
대부분 친숙할 IPv4를 바탕으로 정리해보자!! 이게 뭔 숫자들이여 싶은 주소 양식엔
사실 네트워크에 대한 주소와 호스트에 대한 주소가 구분돼있다!!
네트워크 주소와 호스트 주소
# 네트워크 주소 : 호스트들이 속해있는 특정 네트워크를 식별하는 ID다!! "어데서 온 놈이고?"
# 호스트 주소 : 네트워크 속 특정 호스트를 식별하는 ID다!! "뭐하는 놈이고?"
두 주소는 하나의 IP 주소의 비트들을 나누어 갖는데, 이때 나누는 비율은 네트워크 환경에 따라 달라진다!!
하나의 네트워크에 무수히 많은 호스트가 있다면, 호스트를 더 많이 식별해야하니 호스트 주소의 비중이 커질 것이고,
반대로 호스트는 적은 편인데 거쳐야할 네트워크가 많다면, 네트워크 주소의 비중이 커지겄지요?!
IP 주소의 Class
클래스에는 A부터 E까지 다섯 종류가 있지만, D와 E는 멀티캐스트란 특수 목적을 위한 클래스이므로,
일반적인 경우인 A, B, C 클래스들을 알아보도록 하자!!
# A 클래스 : 네트워크 주소가 1개의 옥텟을, 호스트 주소가 나머지 3개의 옥텟을 차지함!!
# B 클래스 : 네트워크 주소와 호스트 주소가 사이 좋게 2개의 옥텟을 나누어 가진다!!
# C 클래스 : 네트워크 주소가 3개의 옥텟을, 호스트 주소가 나머지 1개의 옥텟을 가진다!!
첫 옥텟의 10진수가 0에서 127 사이라면 A 클래스, 128에서 191 사이면 B 클래스,
192에서 223 사이면 C 클래스이니 아는 척에 활용하도록 하자!!
이렇게 클래스 개념을 바탕으로 주소를 관리하면 클래스풀 주소 체계 Classful Addressing이라 하고, 클래스에 구애 받지 않는 방식이라면 클래스리스 주소 체계 Classless Addressing이라 한다!! 우리는 후자를 주로 활용하며 살아가고 있다!
2-6. 서브넷 마스크
등장 이유
클래스는 네트워크 주소의 크기를 딱 8비트 단위(1 옥텟 씩)로만 칼같이 설정한다!!
네트워크 주소 표현에 딱 9비트만 필요한 상황일지라도, 울며 겨자먹기로 16비트의 B클래스를 써야되니,
클래스풀한 주소 체계에선 7비트나 낭비되는 속상함이 있겄지??
이에 보다 유동적이고 정교하게 구획하기 위하여 클래스리스 주소 체계를 활용하고,
이 Classless한 주소 표현을 도와주는 것이 바로 서브넷 마스크 되시겄다!!
서브넷 마스크 SubNetwork Mask
네트워크 속의 부분적인 네트워크 (subnetwork)를 구분지어 표시하는 (masking) 비트열
서브넷 마스크 표현 양식

위 사진 처럼, IP 주소 옆에 붙은 32 크기의 비트열이다!!
네트워크 주소를 위한 비트는 1로, 호스트 주소를 위한 비트는 0으로 표기한다!!
11111111.10000000.00000000.00000000 이런 식으로 딱 9비트만 필요한 네트워크 주소 표현도 가능해지겄지?!
C클래스 유형의 IP 주소라면, 서브넷 마스크는 11111111.11111111.11111111.00000000 이렇게 되겄지!!
서브네팅 Subnetting
IP 주소와 서브넷 마스크를 AND 비트 연산하면 그 IP 주소의 네트워크 주소를 얻을 수 있고, 이를 Subnetting이라 함!!
AND 비트 연산
피연산자 둘 모두가 1일 때만 1을 반환하고, 그 외의 경우엔 0을 반환한다!!
예) 1111과 1001을 Bitwise AND Operation → 1001 반환
CIDR 표기법

Classless Inter-Domain Routing notoation
비트열 전부를 매번 표기하는 건 읽기도 어렵고 번잡하니까는, 비트열에서 1의 개수로 서브넷 마스크를 표기하는 방식!!
C클래스 유형의 IP 주소라면, 네트워크 주소가 24비트를 차지할 테니 (=1의 개수가 24개일 테니)
192.168.219.103/24 이런 식으로 표현되겄지!!
IPv6 주소 체계에서는?
동일한 방식으로 표현하지만, 명칭이 프리픽스 Prefix로 다르다!!
3. 라우팅 Routing
3-1. 라우팅 테이블
패킷은 송신 호스트와 수신 호스트 사이에 있는 여러 라우터들을 깡총깡총 거쳐서(=Hop) 이동하게 되는데,
이때 라우터에서 경로를 판단하고 설정하기 위해 참고하는 정보들을 라우팅 테이블이라고 한다!!
이 라우팅 테이블이 어떻게 만들어지느냐, 테이블에 어떤 내용이 채워지느냐에 따라 라우팅의 유형을 구분한다!!
라우팅 테이블의 내용들은 라우팅 방식이나, 호스트들의 환경에 따라 달라질 수 있지만,
웬만하면 포함되는 주요 필드들 몇 가지를 알아보도록 하자!!
수신 호스트의 IP 주소 및 서브넷 마스크
패킷이 최종 도달할 대상의 위치를 알려주는 것이지요!!
다음 홉 Next Hop
지금 장치에서 깡총 넘어갈 다음 장치의 IP 주소에 대한 정보를 담는다!!
게이트웨이 Gateway라고 칭하기도 함!!
네트워크 인터페이스 Network Interface Controller

지금 장치에서 패킷이 어디로 나가야할지에 대한 정보를 담는다!!
라우터 기기를 보면 대개 케이블을 꽂는 구멍이 여러 개 있지요?? 그 구멍들 각각이 NIC다!!
메트릭 Metric
설정된 경로로 이동하는 데 소모하는 비용에 대한 정보를 담는다!!
라우팅은 최적의 경로를 찾는 과정이기 때문에, 당연히 이 메트릭이 제일 낮은 경로를 선택하게 된다!!
기본 경로 Default Route
수신지 IP 주소가 잘못됐거나, 찾을 수 없는 경우에, 길 잃은 불쌍한 패킷들을 내보내는 주소 정보를 담는다!!
대개 모든 IP 주소를 의미하는 0.0.0.0/0 형태로 명시한다!!
3-2. 정적 라우팅
직접 운전대 잡기!! 네트워크 관리자가 직접 라우팅 테이블을 설정해 고정된 경로로만 통신이 이뤄지도록 한다!!
# 라우팅 프로토콜로 인한 부가적인 리소스를 절약할 수 있으며,
# 신뢰할 수 있는 경로만 취사선택할 수 있고, 내가 설정한 경로니 통신 과정 예측도 쉬워서 보안 및 관리가 용이하다!!
# 다만 네트워크 복잡도가 올라갈수록 테이블 설정 작업 강도가 심화되고,
# 경로에 문제가 발생하면 수동으로 우회시켜줘야하는 번거로움이 있다!!
따라서 소규모 네트워크나 보안이 중요한 네트워크에서 주로 활용하는 방식!!
3-3. 동적 라우팅
택시 타기!! 라우팅 프로토콜 Routing Protocol 활용을 통해 생성된 라우팅 테이블을 바탕으로 통신 경로를 최적화 하는 방식!!
네트워크에서 이웃한 라우터들끼리 정보를 주고 받으면서 패킷이 이동할 최적의 경로를 그때그때 조정한다!!
라우팅 프로토콜에 일임하니 작업량도 줄어들고, 문제 발생 시에도 알아서 유연하게 대처한다는 장점이 있다!!
AS (Autonomous System)
자율주행할 때 자율이 바로 이 Autonomous다!! 동적 라우팅에서 정보 교환이 이루어지는 라우터 집단을 뜻한다!!
라우터들은 AS 내부에서만 통신할 수도 있고, AS 외부와 통신할 수도 있는데,
후자인 경우 AS의 경계에 위치한 특정 라우터인 ASBR(Autonomous System Boundary Router)을 이용하게 된다!!
라우팅 프로토콜
AS 내부 통신인 경우에 사용되는 프로토콜을 IGP (Interior Gateway Protocol)이라 하고,
AS 외부 통신인 경우엔 EGP (Exterior Gateway Protocol)이라 한다!!
전자에 속하는 대표적인 프로토콜론 RIP와 OSPF가 있고, 후자엔 BGP가 있으니, 각각을 좀 더 알아보도록 하자!!
RIP (Routing Information Protocol)
패킷이 경유할 라우터의 개수, 즉 Hop 횟수를 기준으로 경로를 탐색한다!!
비교적 짧은 주기로 인접 라우터끼리 Hop 횟수를 계산하고, 정보를 교환하고, 라우팅 테이블을 갱신한다!!
Hop 횟수가 적으면 적을수록 라우팅 테이블의 Metric 값이 작아진다!!
공짜가 아니고서야 상식적으로 라우터를 거치는만큼 비용이 발생하겄지?!
따라서 RIP에서는 Hop 횟수가 가장 적은 경로를 목표로 라우팅하게 된다!!
OSPF (Open Shortest Path First)
라우터 간의 관계, 연결 비용 등등 다양한 변수를 고려한 링크 정보 Link State를 통해 경로를 탐색한다!!
RIP처럼 막 자주 소통하진 않고, 대개 네트워크 구성이 변할 때마다 라우팅 테이블을 갱신해 알리게 된다!!
링크 정보는 현재 네트워크의 구성을 지도나 그래프 같은 형태로 그린 것으로,
LSDB(Link State DataBase)에 저장하고, 네트워크 상의 모든 라우터가 이를 참고한다!!
네트워크를 영역 Area이란 개념으로 세분화해 개별적으로 관리하기 때문에, 비교적 대규모 네트워크의 관리도 수월함!!
BGP (Border Gateway Protocol)
AS 내 통신인 이전 두 프로토콜과 달리, AS 간 통신에서 사용되는 프로토콜!! (사실 AS 내 통신도 가능은 함)
친구맺기 Peering 절차가 있다!! 다른 AS와의 연결을 유지하기 위해 BGP 라우터끼리 peer가 되도록 관계를 맺는 것!!
BGP는 라우팅 과정에서 수신지나 경로 뿐 아니라 다양한 정책 Policy이나 속성 Attribute를 고려해야하기 때문에,
비교적 경로 설정이 복잡하고, 일정하지 않음
정책 Policy
AS의 관리 주체에 따라 정해지는 AS 별 통신 규칙
특정 AS를 우대하거나 차단할 수도 있고, 안정성을 우선할지, 성능을 우선할지 등을 설정할 수 있음
속성 Attribute
AS의 통신 환경 특성을 나타내는 정보들
- AS-PATH : 데이터가 수신지까지 도달하는 과정에서 거치는 AS들의 목록
- NEXT-HOP : 다음으로 거칠 라우터의 IP 주소
- LOCAL-PREF : AS 내부에서 (local), 어떤 경로를 선호하는지에 (preference) 대한 정보. 일반적으로 다른 속성들보다 우선되며, 정책 Policy의 영향을 받는다!!
'CS 공부' 카테고리의 다른 글
| IOCP 겉핡기 - Blocking과 Non-blocking I/O, Multiplexing, IOCP (0) | 2024.12.23 |
|---|---|
| 전송 계층 - TCP 중심으로 (1) | 2024.12.20 |
| DNS - Domain Name, Name Server, Query, DNS Cache (0) | 2024.12.16 |
| OSI 모델과 7계층 (1) | 2024.12.07 |
| 서버와 클라이언트 (0) | 2024.12.07 |

